分布式系统为什么需要链路追踪?
随着互联网业务快速扩展,软件架构也日益变得复杂,为了适应海量用户高并发请求,系统中越来越多的组件开始走向分布式化,如单体架构拆分为微服务、服务内缓存变为分布式缓存、服务组件通信变为分布式消息,这些组件共同构成了繁杂的分布式网络。
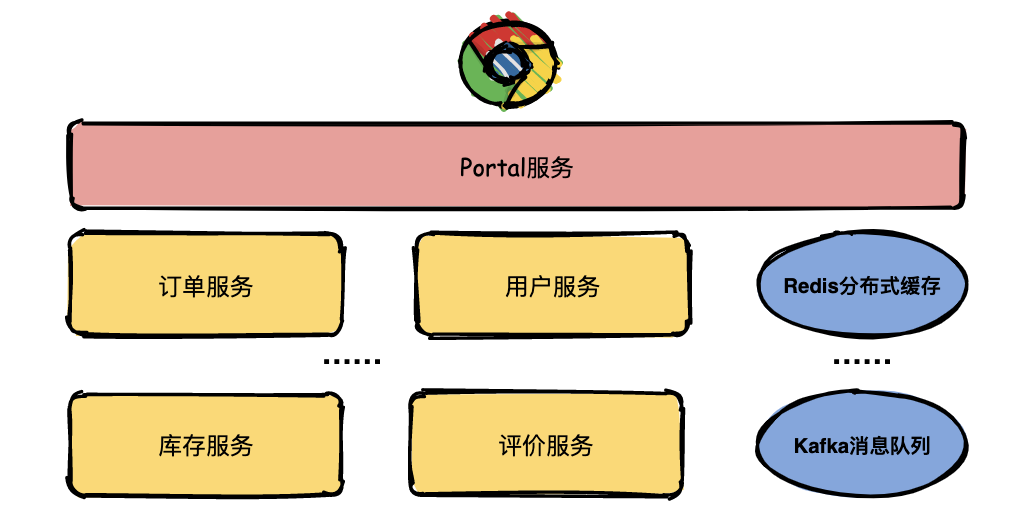
假如现在有一个系统部署了成千上万个服务,用户通过浏览器在主界面上下单一箱茅台酒,结果系统给用户提示:系统内部错误,相信用户是很崩溃的。
运营人员将问题抛给开发人员定位,开发人员只知道有异常,但是这个异常具体是由哪个微服务引起的就需要逐个服务排查了。
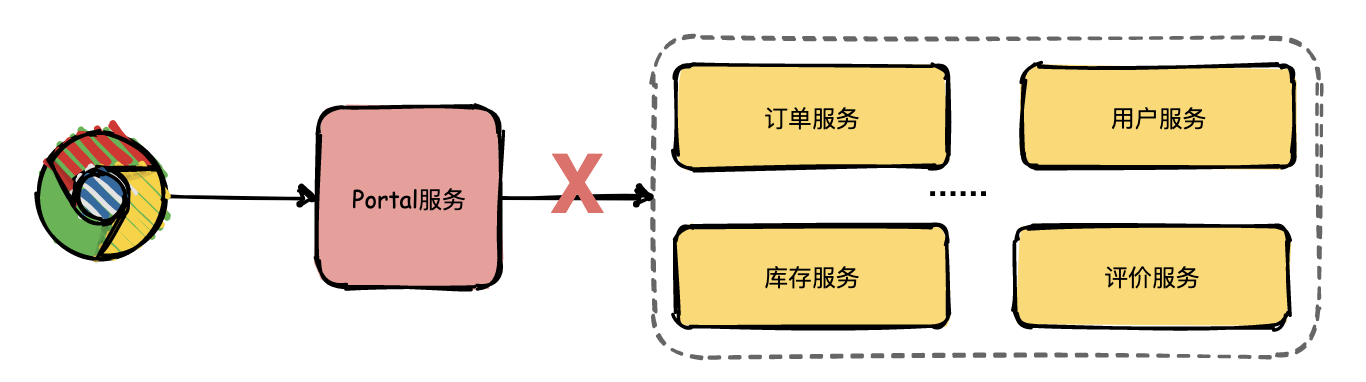
开发人员借助日志逐个排查的效率是非常低的,那有没有更好的解决方案了?答案是引入链路追踪系统。
什么是链路追踪?
分布式链路追踪就是将一次分布式请求还原成调用链路,将一次分布式请求的调用情况集中展示,比如各个服务节点上的耗时、请求具体到达哪台机器上、每个服务节点的请求状态等等。
链路跟踪主要功能:
- 故障快速定位:可以通过调用链结合业务日志快速定位错误信息。
- 链路性能可视化:各个阶段链路耗时、服务依赖关系可以通过可视化界面展现出来。
- 链路分析:通过分析链路耗时、服务依赖关系可以得到用户的行为路径,汇总分析应用在很多业务场景。
链路追踪基本原理
链路追踪系统(可能)最早是由 Google 公开发布的一篇论文 《Dapper, a Large-Scale Distributed Systems Tracing Infrastructure》 被大家广泛熟悉,所以各位技术大牛们如果有黑武器不要藏起来赶紧去发表论文吧。
在这篇著名的论文中主要讲述了 Dapper 链路追踪系统的基本原理和关键技术点。接下来挑几个重点的技术点详细给大家介绍一下。
Trace
Trace 的含义比较直观,就是链路,指一个请求经过所有服务的路径,可以用下面树状的图形表示。
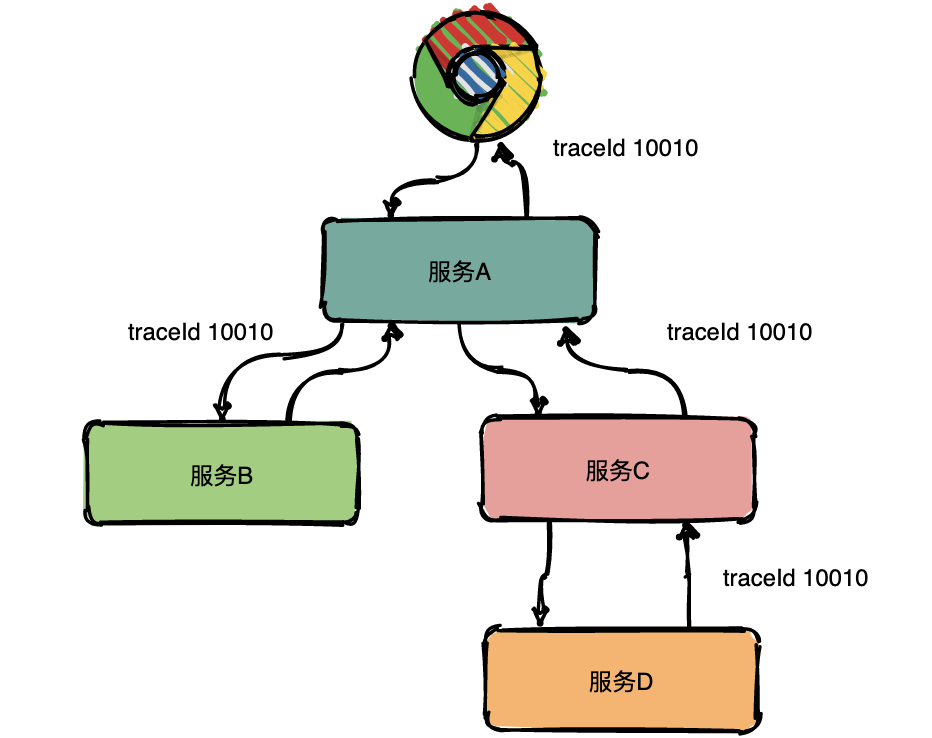
图中一条完整的链路是:chrome -> 服务 A -> 服务 B -> 服务 C -> 服务 D -> 服务 E -> 服务 C -> 服务 A -> chrome。服务间经过的局部链路构成了一条完整的链路,其中每一条局部链路都用一个全局唯一的 traceid 来标识。
Span
在上图中可以看出来请求经过了服务 A,同时服务 A 又调用了服务 B 和服务 C,但是先调的服务 B 还是服务 C 呢?从图中很难看出来,只有通过查看源码才知道顺序。
为了表达这种父子关系引入了 Span 的概念。
同一层级 parent id 相同,span id 不同,span id 从小到大表示请求的顺序,从下图中可以很明显看出服务 A 是先调了服务 B 然后再调用了 C。
上下层级代表调用关系,如下图服务 C 的 span id 为 2,服务 D 的 parent id 为 2,这就表示服务 C 和服务 D 形成了父子关系,很明显是服务 C 调用了服务 D。
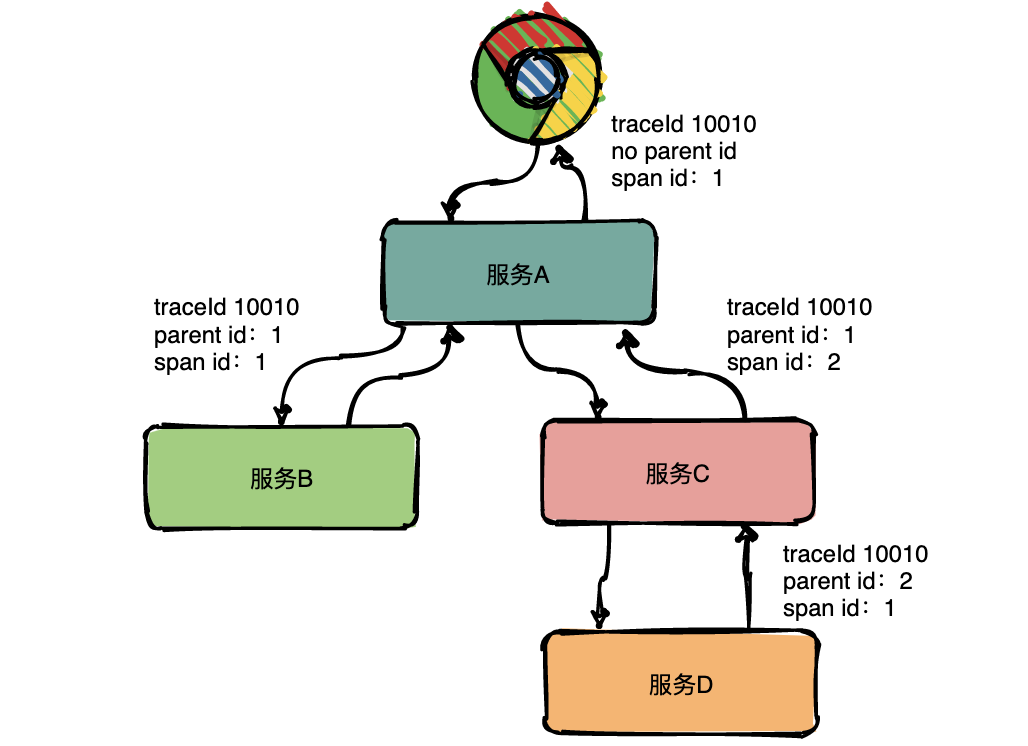
总结:通过事先在日志中埋点,找出相同 traceId 的日志,再加上 parent id 和 span id 就可以将一条完整的请求调用链串联起来。
Annotations
Dapper 中还定义了 annotation 的概念,用于用户自定义事件,用来辅助定位问题。
通常包含四个注解信息: cs:Client Start,表示客户端发起请求; sr:ServerReceived,表示服务端收到请求; ss: Server Send,表示服务端完成处理,并将结果发送给客户端; cr:ClientReceived,表示客户端获取到服务端返回信息;
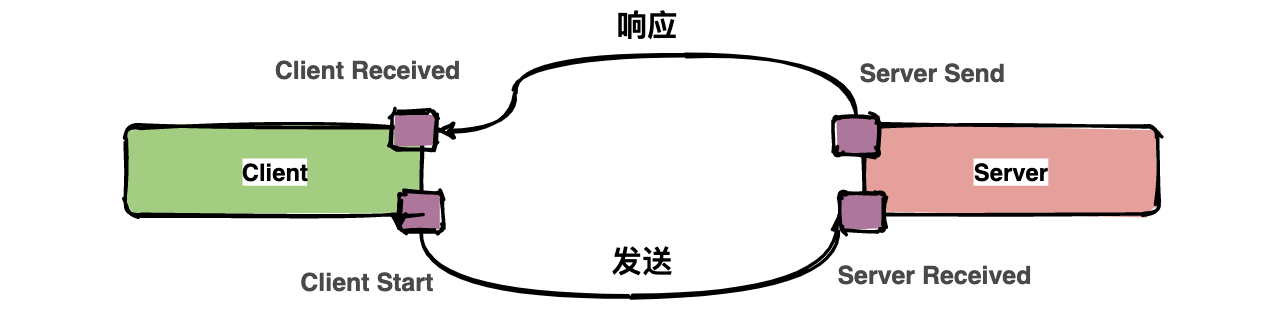
上图中描述了一次请求和响应的过程,四个点也就是对应四个 Annotation 事件。
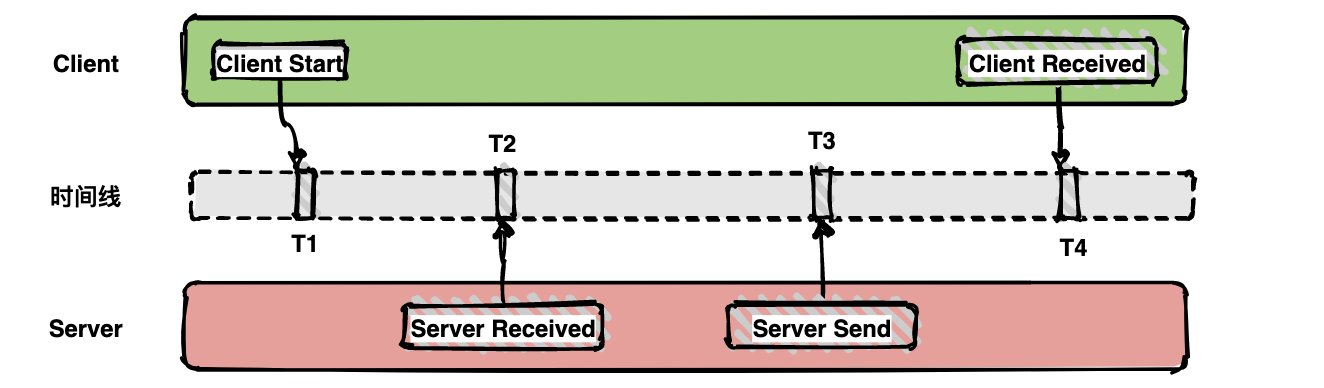
如下面的图表示从客户端调用服务端的一次完整过程。如果要计算一次调用的耗时,只需要将客户端接收的时间点减去客户端开始的时间点,也就是图中时间线上的 T4 - T1。如果要计算客户端发送网络耗时,也就是图中时间线上的 T2 - T1,其他类似可计算。
带内数据与带外数据
链路信息的还原依赖于带内和带外两种数据。
带外数据是各个节点产生的事件,如 cs,ss,这些数据可以由节点独立生成,并且需要集中上报到存储端。通过带外数据,可以在存储端分析更多链路的细节。
带内数据如 traceid,spanid,parentid,用来标识 trace,span,以及 span 在一个 trace 中的位置,这些数据需要从链路的起点一直传递到终点。 通过带内数据的传递,可以将一个链路的所有过程串起来。
采样
由于每一个请求都会生成一个链路,为了减少性能消耗,避免存储资源的浪费,dapper 并不会上报所有的 span 数据,而是使用采样的方式。举个例子,每秒有 1000 个请求访问系统,如果设置采样率为 1/1000,那么只会上报一个请求到存储端。
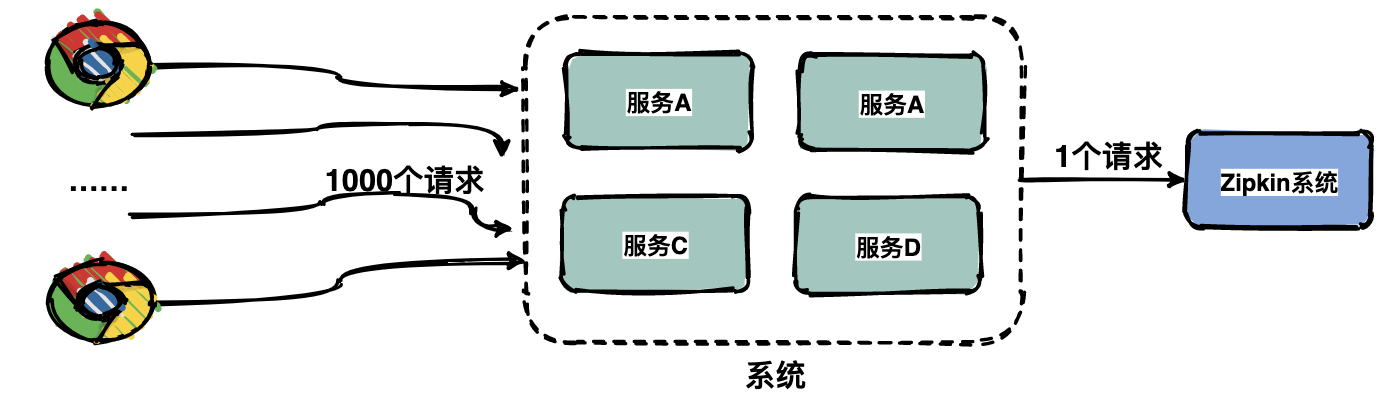
通过采集端自适应地调整采样率,控制 span 上报的数量,可以在发现性能瓶颈的同时,有效减少性能损耗。
存储
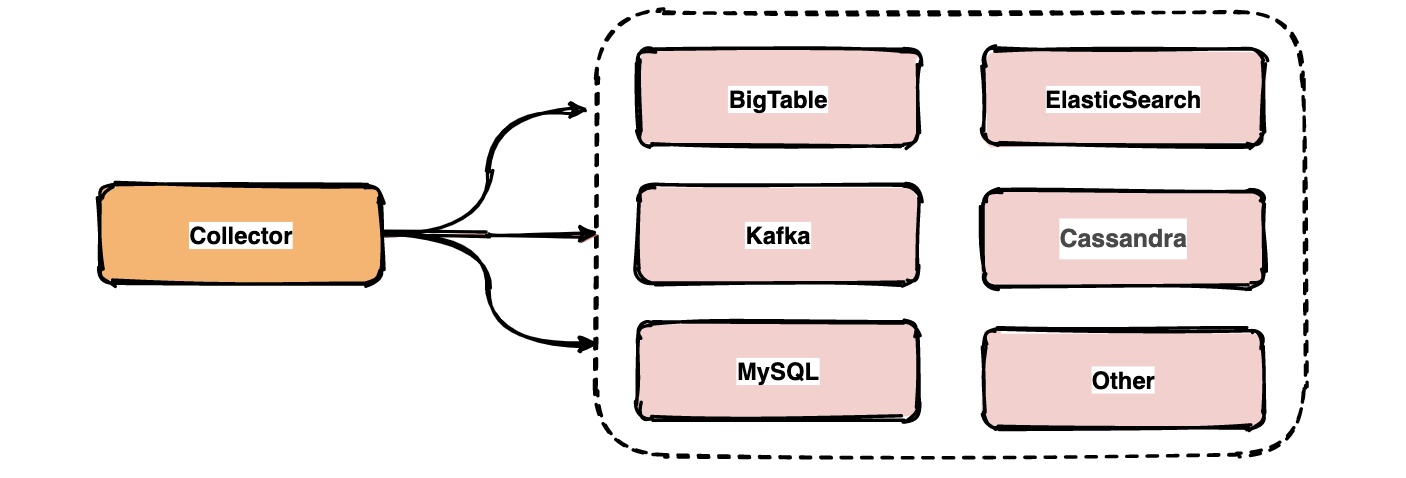
链路中的 span 数据经过收集和上报后会集中存储在一个地方,Dapper 使用了 BigTable 数据仓库,常用的存储还有 ElasticSearch, HBase, In-memory DB 等。
业界常用链路追踪系统
Google Dapper 论文发出来之后,很多公司基于链路追踪的基本原理给出了各自的解决方案,如 Twitter 的 Zipkin,Uber 的 Jaeger,pinpoint,Apache 开源的 skywalking,还有国产如阿里的鹰眼,美团的 Mtrace,滴滴 Trace,新浪的 Watchman,京东的 Hydra,不过国内的这些基本都没有开源。
为了便于各系统间能彼此兼容互通,OpenTracing 组织制定了一系列标准,旨在让各系统提供统一的接口。
下面对比一下几个开源组件,方便日后大家做技术选型。
| zipkin | jaeger | skywalking | |
|---|---|---|---|
| Opentracing 兼容 | 是 | 是 | 是 |
| 客户端支持语言 | Java、c#、go、php、python 等 | Java、c#、go、php、python 等 | Java、.NET Core、NodeJS、php、python 等 |
| 存储 | ES、mysql、Cassandra、内存 | ES、kafka、Cassandra、内存 | ES、H2、mysql、TIDB、shardsphere |
| 传输协议 | http、MQ | upd、http | grpc |
| ui 丰富程度 | 低 | 中 | 中 |
| 实现方式 - 代码侵入性 | 高 | 高 | 中 |
| 扩展性 | 拦截请求,倾入 | 拦截请求,侵入 | 字节码注入,无侵入 |
| trace 查询 | 支持 | 支持 | 支持 |
| 性能损失 | 中 | 中 | 低 |
附各大开源组件的地址:
- zipkin https://zipkin.io
- Jaeger https://www.jaegertracing.io
- SkyWalking http://skywalking.apache.org
因为 Jaeger 是 Go 开发的,项目中主要使用 Jaeger。
Jaeger
Jaeger 是一个分布式追踪系统。Jaeger 的灵感来自 Dapper 和 OpenZipkin,是一个由 Uber 创建并捐赠给 云原生计算基金会(CNCF) 的分布式跟踪平台。它可以用于监控基于微服务的分布式系统:
- 分布式上下文传递
- 分布式事务监听
- 根因分析
- 服务依赖性分析
- 性能/延迟优化
基本架构
Jaeger 组件
Jaeger Client
为不同语言实现了符合 OpenTracing 标准的 SDK。应用程序通过 API 写入数据,client library 把 trace 信息按照应用程序指定的采样策略传递给 jaeger-agent。
Agent
它是一个监听在 UDP 端口上接收 span 数据的网络守护进程,它会将数据批量发送给 collector。它被设计成一个基础组件,部署到所有的宿主机上。Agent 将 client library 和 collector 解耦,为 client library 屏蔽了路由和发现 collector 的细节。
Collectot
接收 jaeger-agent 发送来的数据,然后将数据写入后端存储。Collector 被设计成无状态的组件,因此您可以同时运行任意数量的 jaeger-collector。
Data Store
后端存储被设计成一个可插拔的组件,支持将数据写入 cassandra、elastic search。
Query
接收查询请求,然后从后端存储系统中检索 trace 并通过 UI 进行展示。Query 是无状态的,您可以启动多个实例,把它们部署在 nginx 这样的负载均衡器后面。
总结
- 业界常用的开源组件都是基于谷歌 Dapper 论文演变而来。
- 分布式链路追踪就是将每一次分布式请求还原成调用链路。
- 链路追踪的核心概念:Trace、Span、Annotation、带内和带外数据、采样、存储。
- 分布式追踪系统种类众多,但核心步骤只有三个:代码埋点、数据存储、查询展示。