微服务负载均衡的模式
集中式负载均衡
首先,服务的消费方和提供方不直接耦合,而是在服务消费者和服务提供者之间有一个独立的负载均衡器(通常是专门的硬件设备如 F5,或者基于软件如 LVS,Nginx 等实现)。这种模式在单体应用中普遍采用。
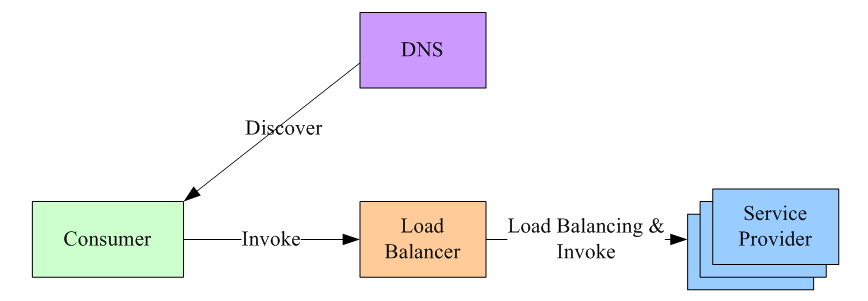
LB 上有所有服务的地址映射表,通常由运维配置注册,当服务消费方调用某个目标服务时,它向 LB 发起请求,由 LB 以某种策略(比如 Round-Robin)做负载均衡后将请求转发到目标服务。
LB 一般具备健康检查能力,能自动摘除不健康的服务实例。
服务消费方如何发现 LB 呢?通常的做法是通过 DNS,运维人员为服务配置一个 DNS 域名,这个域名指向 LB。
这种方案基本可以否决,因为它有致命的缺点:所有服务调用流量都经过 load balance 服务器,所以 load balance 服务器成了系统的单点,一旦 LB 发生故障对整个系统的影响是灾难性的。为了解决这个问题,必然需要对这个 load balance 部件做分布式处理(部署多个实例,冗余,然后解决一致性问题等全家桶解决方案),但这样做会徒增非常多的复杂度。
进程内负载均衡(推荐)
进程内 load balance。将 load balance 的功能和算法以 sdk 的方式实现在客户端进程内。先看架构图:
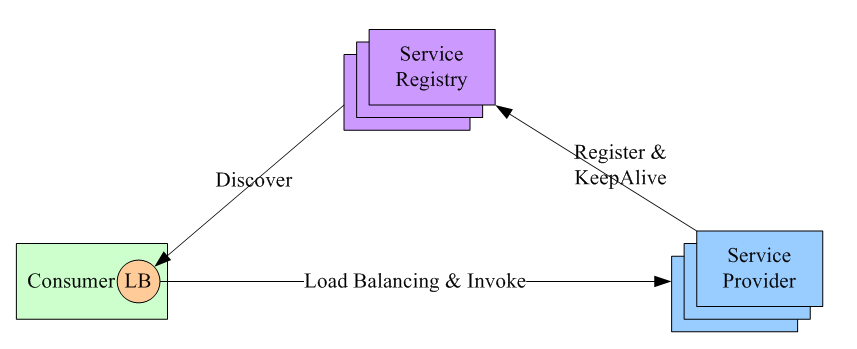
可看到引入了第三方:服务注册中心。它做两件事:
- 维护服务提供方的节点列表,并检测这些节点的健康度。检测的方式是:每个节点部署成功,都通知服务注册中心;然后一直和注册中心保持心跳。
- 允许服务调用方注册感兴趣的事件,把服务提供方的变化情况推送到服务调用方。
这种方案下,整个 load balance 的过程是这样的:
- 服务注册中心维护所有节点的情况。
- 任何一个节点想要订阅其他服务提供方的节点列表,向服务注册中心注册。
- 服务注册中心将服务提供方的列表(以长连接的方式)推送到消费方。
- 消费方接收到消息后,在本地维护一份这个列表,并自己做 load balance。
可见,服务注册中心充当什么角色?它是唯一一个知道整个集群内部所有的节点情况的中心。所以对它的可用性要求会非常高,这个组件可以用 Zookeeper 实现。
这种方案的缺点是:每个语言都要研究一套 sdk,如果公司内的服务使用的语言五花八门的话,这方案的成本会很高。第二点是:后续如果要对客户库进行升级,势必要求服务调用方修改代码并重新发布,所以该方案的升级推广有不小的阻力。
独立进程负载均衡
该方案是针对第二种方案的不足而提出的一种折中方案,原理和第二种方案基本类似,不同之处是,他将 LB 和服务发现功能从进程内移出来,变成主机上的一个独立进程,主机上的一个或者多个服务要访问目标服务时,他们都通过同一主机上的独立 LB 进程做服务发现和负载均衡。如图
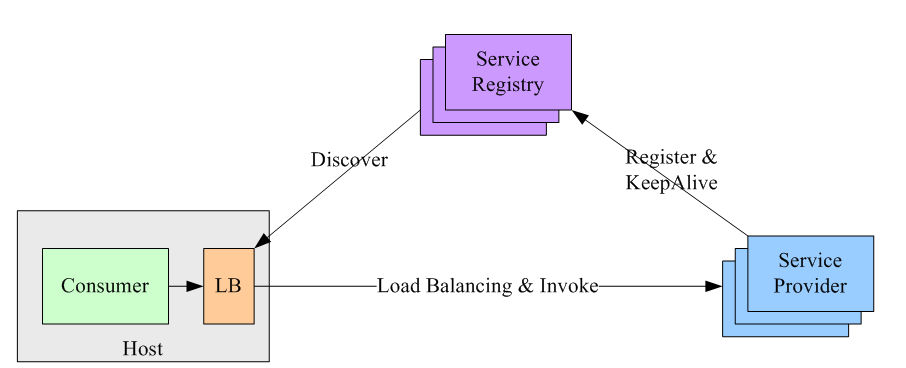
这个方案解决了上一种方案的问题,不需要为不同语言开发客户库,LB 的升级不需要服务调用方改代码。
但新引入的问题是:这个组件本身的可用性谁来维护?还要再写一个 watchdog 去监控这个组件?另外,多了一个环节,就多了一个出错的可能,线上出问题了,也多了一个需要排查的环节。
常见的负载均衡算法
在分布式系统中,多台服务器同时提供一个服务,并统一到服务配置中心进行管理,消费者通过查询服务配置中心,获取到服务到地址列表,需要选取其中一台来发起 RPC 远程调用。如何选择,则取决于具体的负载均衡算法,对应于不同的场景,选择的负载均衡算法也不尽相同。负载均衡算法的种类有很多种,常见的负载均衡算法包括轮询法、随机法、源地址哈希法、加权轮询法、加权随机法、最小连接法等,应根据具体的使用场景选取对应的算法。
轮询(Round Robin)
轮询很容易实现,将请求按顺序轮流分配到后台服务器上,均衡的对待每一台服务器,而不关心服务器实际的连接数和当前的系统负载。
随机法
通过系统随机函数,根据后台服务器列表的大小值来随机选取其中一台进行访问。由概率概率统计理论可以得知,随着调用量的增大,其实际效果越来越接近于平均分配流量到后台的每一台服务器,也就是轮询法的效果。
源地址哈希
源地址哈希法的思想是根据服务消费者请求客户端的 IP 地址,通过哈希函数计算得到一个哈希值,将此哈希值和服务器列表的大小进行取模运算,得到的结果便是要访问的服务器地址的序号。采用源地址哈希法进行负载均衡,相同的 IP 客户端,如果服务器列表不变,将映射到同一个后台服务器进行访问。
加权轮询(Weight Round Robin)
不同的后台服务器可能机器的配置和当前系统的负载并不相同,因此它们的抗压能力也不一样。跟配置高、负载低的机器分配更高的权重,使其能处理更多的请求,而配置低、负载高的机器,则给其分配较低的权重,降低其系统负载,加权轮询很好的处理了这一问题,并将请求按照顺序且根据权重分配给后端。
加权随机(Weight Random)
加权随机法跟加权轮询法类似,根据后台服务器不同的配置和负载情况,配置不同的权重。不同的是,它是按照权重来随机选取服务器的,而非顺序。
最小连接数法
前面我们费尽心思来实现服务消费者请求次数分配的均衡,我们知道这样做是没错的,可以为后端的多台服务器平均分配工作量,最大程度地提高服务器的利用率,但是,实际上,请求次数的均衡并不代表负载的均衡。因此我们需要介绍最小连接数法,最小连接数法比较灵活和智能,由于后台服务器的配置不尽相同,对请求的处理有快有慢,它正是根据后端服务器当前的连接情况,动态的选取其中当前积压连接数最少的一台服务器来处理当前请求,尽可能的提高后台服务器利用率,将负载合理的分流到每一台服务器。
小结
这些策略可以根据具体的应用需求和场景进行选择和组合。此外,还有其他更复杂的策略,如基于响应时间、动态调整权重等,以满足特定的负载均衡需求。
需要注意的是,最适合的负载均衡策略取决于具体的应用场景和系统特点。选择合适的负载均衡策略需要考虑服务器性能、网络拓扑、请求特征等因素,并进行实际的性能测试和评估。
gRpc 负载均衡
文档
https://github.com/grpc/grpc/blob/master/doc/load-balancing.md
Package
示例代码
先注册两个 gRpc 服务实例
package main
import (
"context"
"demo1/grpc_resolve/proto"
"fmt"
_ "github.com/mbobakov/grpc-consul-resolver" // It's important
"google.golang.org/grpc"
"google.golang.org/grpc/credentials/insecure"
)
func main() {
conn, err := grpc.Dial("consul://192.168.1.6:8500/user-srv?wait=15s&tag=user",
grpc.WithTransportCredentials(insecure.NewCredentials()),
grpc.WithDefaultServiceConfig(`{"loadBalancingPolicy": "round_robin"}`),
)
if err != nil {
panic(err)
}
defer conn.Close()
userSrvClient := proto.NewUserClient(conn)
// 因为负载均衡实现是进程中的,必须要进程结束前发起请求才被内负载均衡
for i := 0; i < 10; i++ {
rsp, err := userSrvClient.GetUserList(context.Background(), &proto.PageInfo{
Pn: 1,
PSize: 2,
})
if err != nil {
panic(err)
}
for index, data := range rsp.Data {
fmt.Println(index, data)
}
}
}
服务退出注销服务
// 优雅退出 接收终止信号
quit := make(chan os.Signal)
signal.Notify(quit, syscall.SIGINT, syscall.SIGTERM)
<-quit
if err = client.Agent().ServiceDeregister(registration.ID); err != nil {
fmt.Println("注销失败")
}
fmt.Println("注销成功")