服务雪崩
一条服务调用链路,服务 A 调 服务 B ,服务 B 调 服务 C,如果服务 C 调用失败,那么服务 B 的请求会阻塞,慢慢的,服务 B 会变得不可用,接着,服务 A 也会不可用。
一个服务失败,导致整条链路的服务都失败的情形,我们称之为「 服务雪崩 」。
解决服务雪崩的手段有「 服务熔断 」和「 服务降级 」。
服务熔断
服务熔断:当下游服务因访问压力过大而响应变慢或失败,上游服务为了保护系统整体的可用性,可以暂时切断对下游服务的调用,直接返回,快速释放资源。如果目标服务情况好转则恢复调用。
目前熔断器有,阿里出的 Sentinel,Netfilx 的 Hystrix 和 基于 Hystrix 实现的 Spring Cloud Hystrix。
熔断设计 三个模块:熔断请求判断算法、熔断恢复机制、熔断报警
熔断请求判断算法
使用无锁循环队列计数,每个熔断器默认维护 10 个 bucket,每 1 秒一个 bucket,每个 blucket 记录请求的成功、失败、超时、拒绝的状态,默认错误超过 50% 且 10 秒内超过 20 个请求进行中断拦截。
熔断恢复机制
对于被熔断的请求,每隔 5s 允许部分请求通过,若请求都是健康的(RT<250ms)则对请求健康恢复。
熔断报警
对于熔断的请求打日志,异常请求超过某些设定则报警。
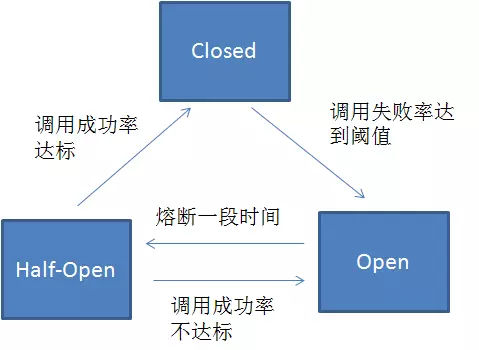
-
最开始,服务没有故障时,熔断器处于 closed 状态。
-
在固定时间内(Hystrix 默认是 10 秒),接口调用出错比率达到一个阈值时( Hystrix 默认为 50%),会进入熔断开启状态。进入熔断状态后,后续对该服务接口的调用不再经过网络,直接执行本地的 fallback 方法。
-
在进入熔断开启状态一段时间之后(Hystrix 默认是 5 秒),熔断器会进入 half-open 半熔断状态。所谓半熔断就是尝试恢复服务调用,允许有限的流量调用该服务,并监控调用成功率。如果成功率达到预期,则说明服务已恢复,进入熔断关闭状态;如果成功率仍旧很低,则重新进入熔断开启状态。
-
在尝试一段时间后,服务还没有恢复,则进入本地的服务降级的逻辑处理。
参考: 漫画:什么是服务熔断?
服务降级
当服务器压力剧增的情况下,为了保证重要或基本的服务能正常运行,选择性的将一些 不重要 或 不紧急 的服务或任务进行服务的 延迟使用 或 暂停使用,为了保证功能的可用性,调用本地的一些降级逻辑处理。
服务降级要考虑的问题:
-
核心和非核心服务
-
是否支持降级,降级策略
-
业务放通的场景,策略
降级分类
降级按照是否自动化可分为:自动开关降级和人工开关降级。
降级按照功能可分为:读服务降级、写服务降级。
降级按照处于的系统层次可分为:多级降级。
降级策略
- 限流降级
- 熔断降级
- 页面拒绝服务:页面提示由于服务繁忙此服务暂停
- 延迟持久化:页面访问照常,但是涉及记录变更,会提示稍晚能看到结果,将数据记录到异步队列或 log,服务恢复后执行。
降级与熔断区别是什么?
- 触发原因不太一样,服务熔断一般是某个服务(下游服务)故障引起,而服务降级一般是从整体负荷考虑。
- 熔断可以理解为实现服务降级的一种手段。进入熔断状态后,后续对该服务接口的调用不再经过网络,直接执行本地的默认方法,达到服务降级的效果。
如何实现自动降级?
-
超时降级:主要配置好超时时间和超时重试次数和机制,并使用异步机制探测恢复情况。
-
失败次数降级:主要是一些不稳定的 API,当失败调用次数达到一定阀值自动降级,同样要使用异步机制探测恢复情况。
-
故障降级:如要调用的远程服务挂掉了(网络故障、DNS 故障、HTTP 服务返回错误的状态码和 RPC 服务抛出异常),则可以直接降级。
-
限流降级:当触发了限流超额时,可以使用暂时屏蔽的方式来进行短暂的屏蔽。
参考:微服务架构—服务降级
服务限流
系统规定了多少承受能力,只允许这么些请求能过来,其他的请求直接拒绝。
一般限制的指标有:请求总量或某段时间内请求总量。
- 请求总量:比如秒杀的,秒杀 100 份产品,我就放 5000 名进来,超过的直接拒绝请求了。
- 某段时间内请求总量:比如规定了每秒请求的峰值是 1W,这一秒内多的请求直接拒绝了。
解决方案
- 排队等待
- 拒绝响应:如前端返回静态页面,当前访问用户过多,请稍后再试
优点
在高并发中,限流是很重要的手段,可以防止服务器资源无节制的扩容,同时可以避免系统崩溃。
缺点
用户体验不好